CART-MPC: Coordinating Assistive Devices for Robot-Assisted Transferring with Multi-Agent Model Predictive Control
Ruolin Ye1,†, Shuaixing Chen1,2,†, Yunting Yan1,†, Joyce Yang1, Christina Ge1, Jose Barreiros3, Kate Tsui3, Tom Silver1, Tapomayukh Bhattacharjee1
1Cornell University, 2Shanghai Jiao Tong University, 3Toyota Research Institute
†Equal contribution
Abstract
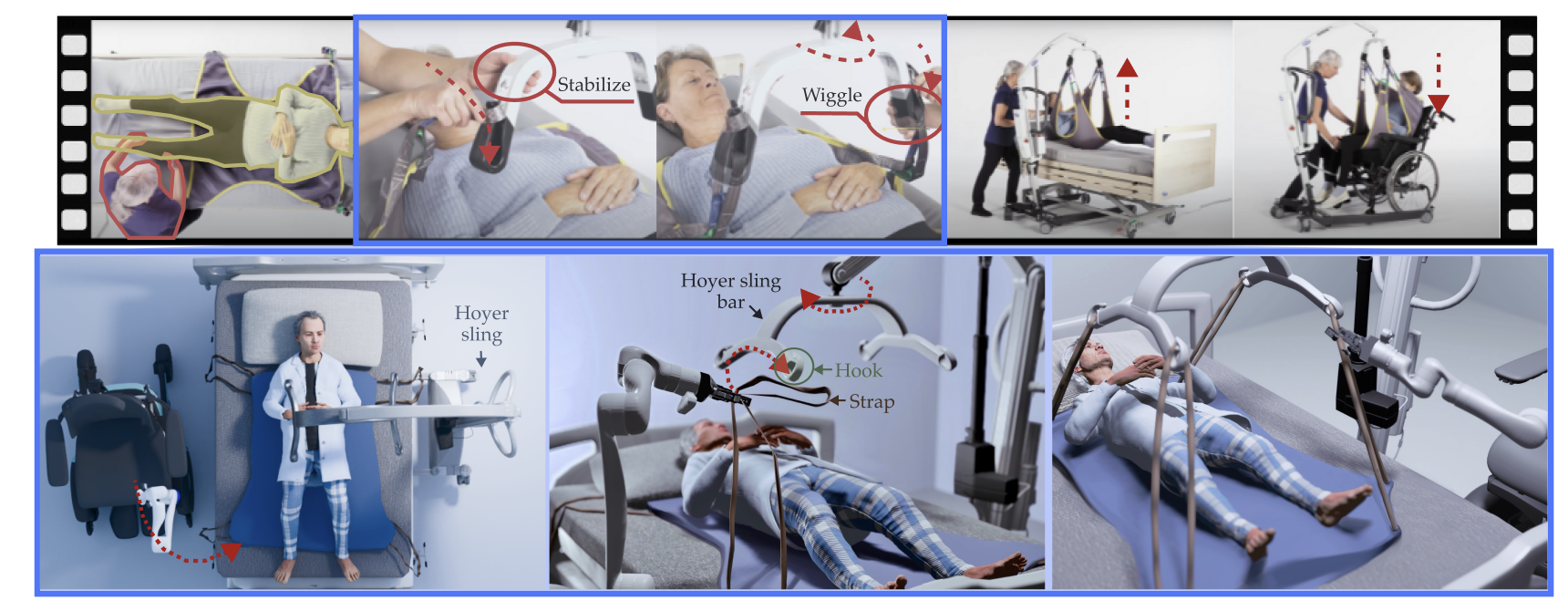
Bed-to-wheelchair transferring is a ubiquitous activity of daily living (ADL), but especially challenging for caregiving robots with limited payloads. We develop a novel algorithm that leverages the presence of other assistive devices: a Hoyer sling and a wheelchair for coarse manipulation of heavy loads, alongside a robot arm for fine-grained manipulation of deformable objects (Hoyer sling straps). We instrument the Hoyer sling and wheelchair with actuators and sensors so that they can become intelligent agents in the algorithm. We then focus on one subtask of the transferring ADL---tying Hoyer sling straps to the sling bar---that exemplifies the challenges of transfer: multi-agent planning, deformable object manipulation, and generalization to varying hook shapes, sling materials, and care recipient bodies. To address these challenges, we propose CART-MPC, a novel algorithm based on turn-taking multi-agent model predictive control that uses a learned neural dynamics model for a keypoint-based representation of the deformable Hoyer sling strap, and a novel cost function that leverages linking numbers from knot theory and neural amortization to accelerate inference. We validate it in both RCareWorld simulation and real-world environments. In simulation, CART-MPC successfully generalizes across diverse hook designs, sling materials, and care recipient body shapes. In the real world, we show zero-shot sim-to-real generalization capabilities to tie deformable Hoyer sling straps on a sling bar towards transferring a manikin from a hospital bed to a wheelchair.
Pipeline Overview
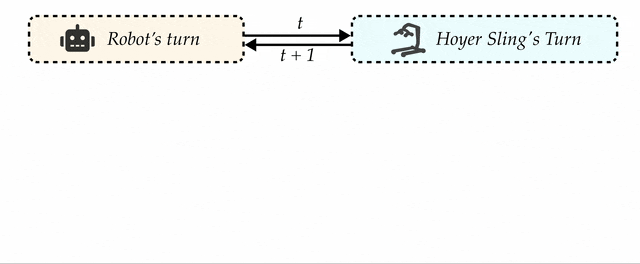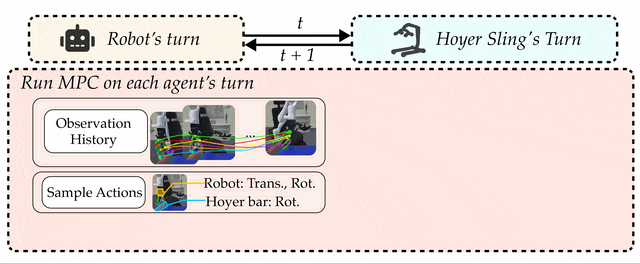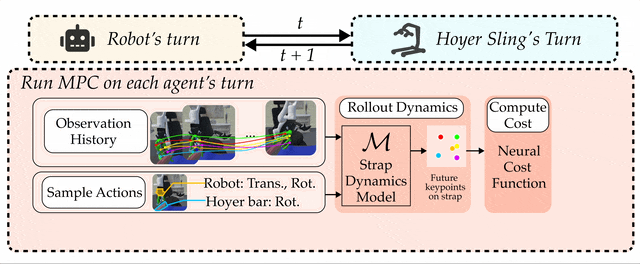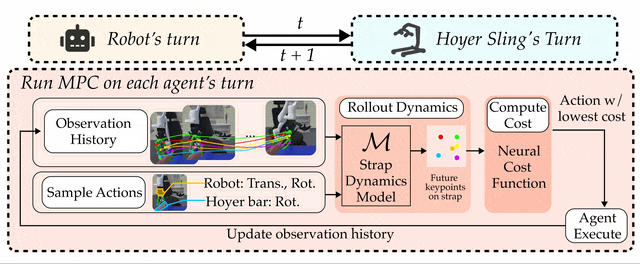
We propose a turn-taking multi-agent algorithm to coordinate the robot and the Hoyer sling bar during strap fastening.
CART-MPC is a decentralized policy with two parts: for the robot and for the Hoyer sling frame bar, where the two agents take turns to perform the task.
Both policies are implemented using multi-agent MPC.
Predictions in the MPC are governed by a learned dynamics model of the strap that operates in keypoint space.
The MPC optimizes a weighted sum of costs, most notably including a novel knot-theory-based cost function (and a neural amortization of it) that represents the degree to which the strap is fastened on the hook.
Try Strap tying
Try it yourself! We provide a simulation environment in RCareWorld for strap tying. See if you can do it. Loading may take a while for the first time.
Linking-number-based Cost Function
The linking number is a numerical invariant that describes the linking of two closed curves in three-dimensional space. Intuitively, the linking number represents the number of times that each curve winds around the other. Inspired by this concept, we use neural-armotized linking number to measure to what extent the strap ties on the hook. As the robot ties the strap on the hook, the linking number increases from 0 to 1.
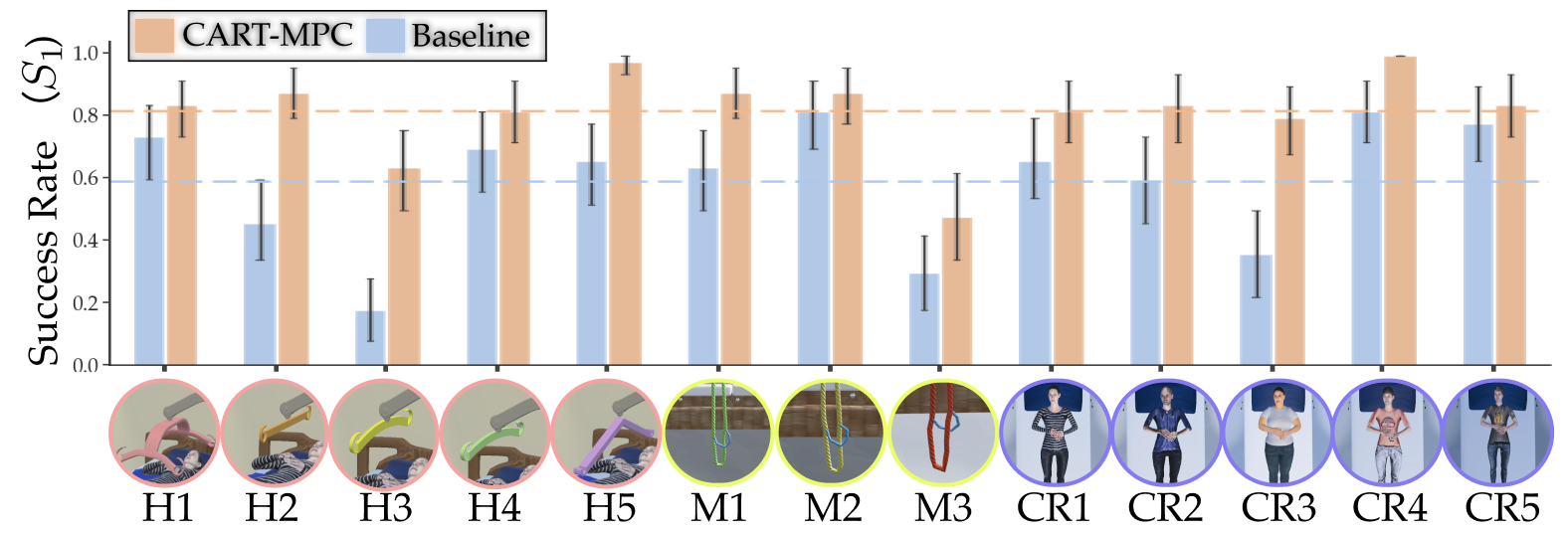
Evaluation in RCareWorld
We train the dynamics model using only Hook 1 and Sling material 1. We show the ability to generalize to various hooks, care recipient body shapes, and sling materials in the following videos.
We ran 50 trials on each setup, resulting in an overall 650 trials. The result is as follows. According to the z-test result, CART-MPC performs statistically significantly better than the baseline (p<0.00001). The variance also resulted in lower as there were more trials.



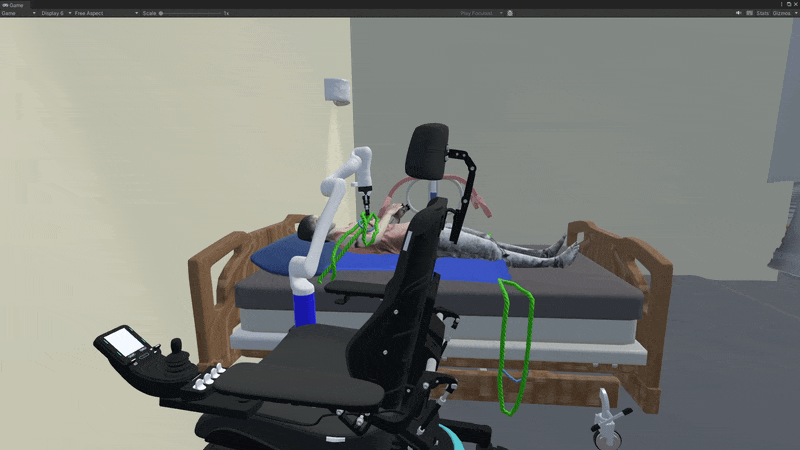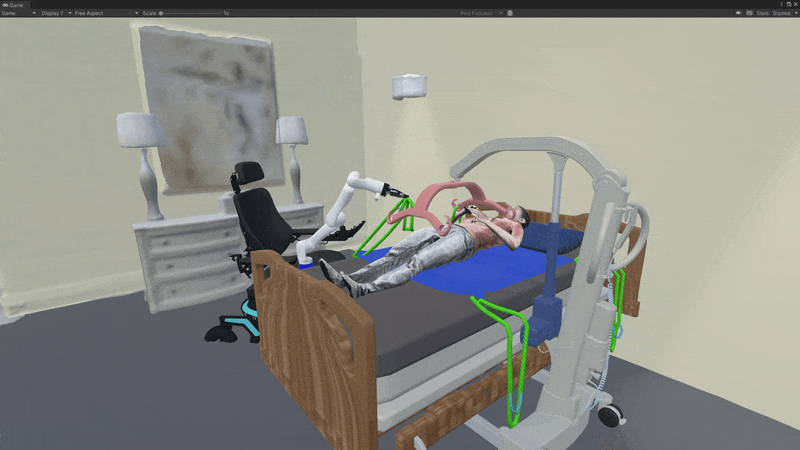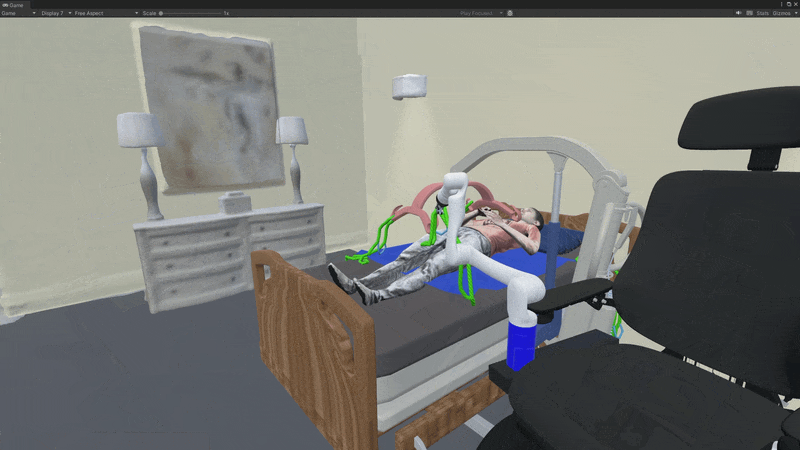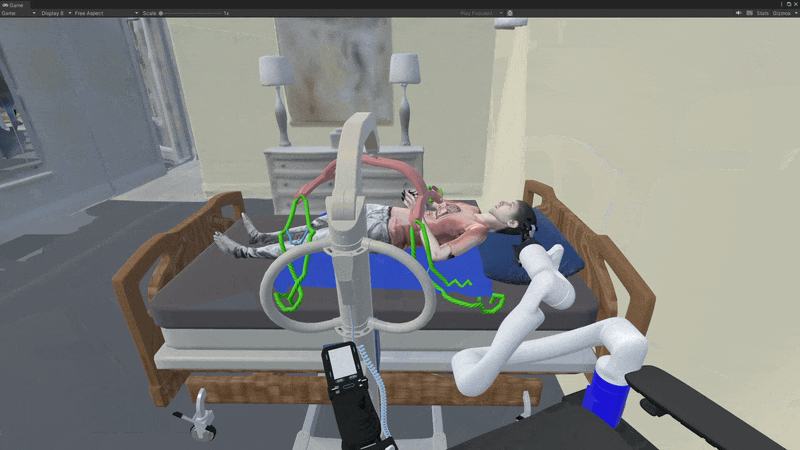








Failure Modes
We provide some observations about why the MPC fails:
- The network sometimes falsely predicts success when the strap is near but not securely tied;
- Trained on a highly deformable strap (M1) and single hook (H1), the dynamics model struggles with rigid straps (M3) due to distributional shift;
- Strap detection and tracking are challenging, with tracking drifting when detection fails.
Comparison with RL
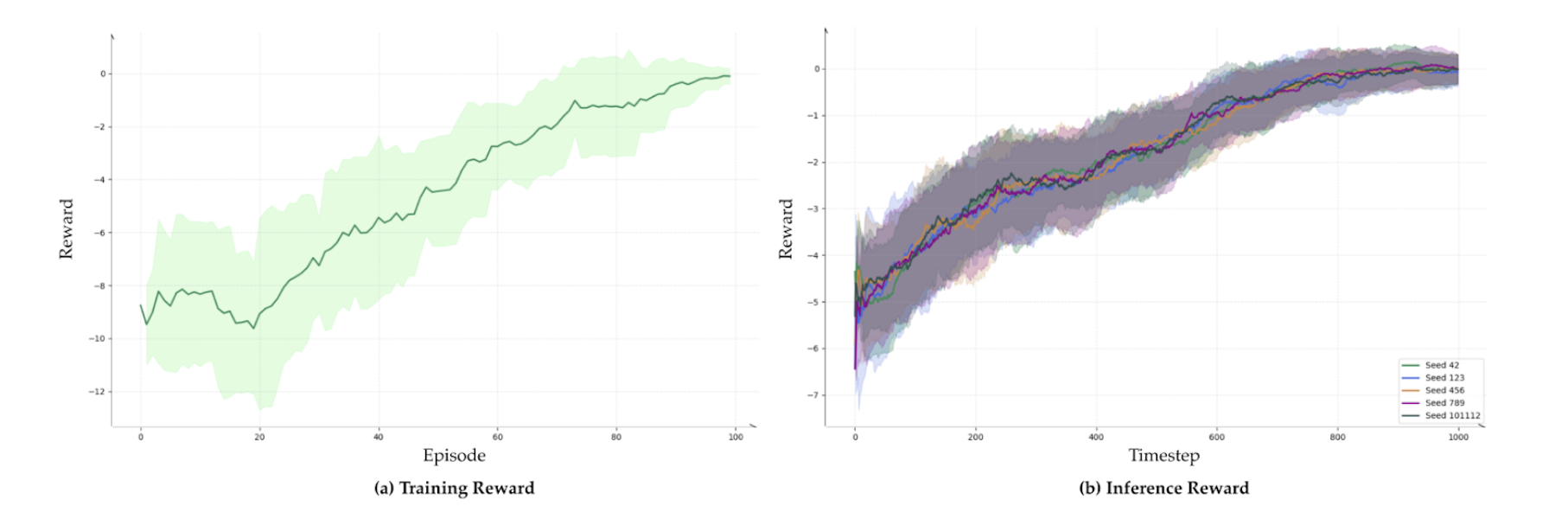
We trained a reinforcement learning baseline using PPO, to compare with the MPC-based approach. Our implementation is based on Stable-baselines3. We extensively train it for 100 episodes with 5 random seeds (42, 123, 456, 789, 10112). We show the training reward and inference reward as the following. Though extensively trained, the success rate is relatively low (0.57). We show some of the examples as the following.
Cite Us
@inproceedings{ye2025cartmpc,
author = {Ruolin Ye and Shuaixing Chen and Yunting Yan and Joyce Yang and Christina Ge and Jose Barreiros and Kate Tsui and Tom Silver and Tapomayukh Bhattacharjee},
title = {CART-MPC: Coordinating Assistive Devices for Robot-Assisted Transferring with Multi-Agent Model Predictive Control},
booktitle = {Proceedings of the 2025 ACM/IEEE International Conference on Human-Robot Interaction (HRI)},
year = {2025},
publisher = {ACM/IEEE}
}